Jonathan Dowland: Our Study
 This is a fairly self-indulgent post, sorry!
Encouraged by Evgeni,
Michael and
others, given I'm spending a lot more time at my desk in my home office, here's
a picture of it:
This is a fairly self-indulgent post, sorry!
Encouraged by Evgeni,
Michael and
others, given I'm spending a lot more time at my desk in my home office, here's
a picture of it:
 Fisheye shot of my home office
This is a fairly self-indulgent post, sorry!
Encouraged by Evgeni,
Michael and
others, given I'm spending a lot more time at my desk in my home office, here's
a picture of it:
Fisheye shot of my home office
Fisheye shot of my home office
This is a fairly self-indulgent post, sorry!
Encouraged by Evgeni,
Michael and
others, given I'm spending a lot more time at my desk in my home office, here's
a picture of it:
Fisheye shot of my home office

library (and later module_utils and doc_fragment_plugins) in ansible.cfg and effectively inject our modules, their helpers and documentation fragments into the main Ansible namespace. Not the cleanest solution, but it worked quiet well for us.
When Ansible started introducing Collections, we quickly joined, as the idea of namespaced, easily distributable and usable content units was great and exactly matched what we had in mind.
However, collections are only usable in Ansible 2.8, or actually 2.9 as 2.8 can consume them, but tooling around building and installing them is lacking. Because of that we've been keeping our modules usable outside of a collection.
Until recently, when we decided it's time to move on, drop that compatibility (which costed a few headaches over the time) and release a shiny 1.0.0.
One of the changes we wanted for 1.0.0 is renaming a few modules. Historically we had the module names prefixed with foreman_ and katello_, depending whether they were designed to work with Foreman (and plugins) or Katello (which is technically a Foreman plugin, but has a way more complicated deployment and currently can't be easily added to an existing Foreman setup). This made sense as long as we were injecting into the main Ansible namespace, but with collections the names be became theforemam.foreman.foreman_ <something> and while we all love Foreman, that was a bit too much. So we wanted to drop that prefix. And while at it, also change some other names (like ptable, which became partition_table) to be more readable.
But how? There is no tooling that would rename all files accordingly, adjust examples and tests. Well, bash to the rescue! I'm usually not a big fan of bash scripts, but renaming files, searching and replacing strings? That perfectly fits!
First of all we need a way map the old name to the new name. In most cases it's just "drop the prefix", for the others you can have some if/elif/fi:
prefixless_name=$(echo $ old_name sed -E 's/^(foreman katello)_//') if [[ $ old_name == 'foreman_environment' ]]; then new_name='puppet_environment' elif [[ $ old_name == 'katello_sync' ]]; then new_name='repository_sync' elif [[ $ old_name == 'katello_upload' ]]; then new_name='content_upload' elif [[ $ old_name == 'foreman_ptable' ]]; then new_name='partition_table' elif [[ $ old_name == 'foreman_search_facts' ]]; then new_name='resource_info' elif [[ $ old_name == 'katello_manifest' ]]; then new_name='subscription_manifest' elif [[ $ old_name == 'foreman_model' ]]; then new_name='hardware_model' else new_name=$ prefixless_name fiThat defined, we need to actually have a
$ old_name . Well, that's a for loop over the modules, right?
for module in $ BASE /foreman_*py $ BASE /katello_*py; do old_name=$(basename $ module .py) doneWhile we're looping over files, let's rename them and all the files that are associated with the module:
# rename the module git mv $ BASE /$ old_name .py $ BASE /$ new_name .py # rename the tests and test fixtures git mv $ TESTS /$ old_name .yml $ TESTS /$ new_name .yml git mv tests/fixtures/apidoc/$ old_name .json tests/fixtures/apidoc/$ new_name .json for testfile in $ TESTS /fixtures/$ old_name -*.yml; do git mv $ testfile $(echo $ testfile sed "s/$ old_name /$ new_name /") doneNow comes the really tricky part: search and replace. Let's see where we need to replace first:
module key of the DOCUMENTATION stanza (e.g. module: foreman_example)foreman_example: )foreman_example: )conftest.py and other files related to test executionsed -E -i "/^(\s+$ old_name module):/ s/$ old_name /$ new_name /g" $ BASE /*.py sed -E -i "/^(\s+$ old_name module):/ s/$ old_name /$ new_name /g" tests/test_playbooks/tasks/*.yml tests/test_playbooks/*.yml sed -E -i "/'$ old_name '/ s/$ old_name /$ new_name /" tests/conftest.py tests/test_crud.py sed -E -i "/ $ old_name / s/$ old_name /$ new_name /g' README.md docs/*.mdYou've probably noticed I used
$ BASE and $ TESTS and never defined them Lazy me.
But here is the full script, defining the variables and looping over all the modules.
#!/bin/bash BASE=plugins/modules TESTS=tests/test_playbooks RUNTIME=meta/runtime.yml echo "plugin_routing:" > $ RUNTIME echo " modules:" >> $ RUNTIME for module in $ BASE /foreman_*py $ BASE /katello_*py; do old_name=$(basename $ module .py) prefixless_name=$(echo $ old_name sed -E 's/^(foreman katello)_//') if [[ $ old_name == 'foreman_environment' ]]; then new_name='puppet_environment' elif [[ $ old_name == 'katello_sync' ]]; then new_name='repository_sync' elif [[ $ old_name == 'katello_upload' ]]; then new_name='content_upload' elif [[ $ old_name == 'foreman_ptable' ]]; then new_name='partition_table' elif [[ $ old_name == 'foreman_search_facts' ]]; then new_name='resource_info' elif [[ $ old_name == 'katello_manifest' ]]; then new_name='subscription_manifest' elif [[ $ old_name == 'foreman_model' ]]; then new_name='hardware_model' else new_name=$ prefixless_name fi echo "renaming $ old_name to $ new_name " git mv $ BASE /$ old_name .py $ BASE /$ new_name .py git mv $ TESTS /$ old_name .yml $ TESTS /$ new_name .yml git mv tests/fixtures/apidoc/$ old_name .json tests/fixtures/apidoc/$ new_name .json for testfile in $ TESTS /fixtures/$ old_name -*.yml; do git mv $ testfile $(echo $ testfile sed "s/$ old_name /$ new_name /") done sed -E -i "/^(\s+$ old_name module):/ s/$ old_name /$ new_name /g" $ BASE /*.py sed -E -i "/^(\s+$ old_name module):/ s/$ old_name /$ new_name /g" tests/test_playbooks/tasks/*.yml tests/test_playbooks/*.yml sed -E -i "/'$ old_name '/ s/$ old_name /$ new_name /" tests/conftest.py tests/test_crud.py sed -E -i "/ $ old_name / s/$ old_name /$ new_name /g' README.md docs/*.md echo " $ old_name :" >> $ RUNTIME echo " redirect: $ new_name " >> $ RUNTIME git commit -m "rename $ old_name to $ new_name " $ BASE tests/ README.md docs/ $ RUNTIME doneAs a bonus, the script will also generate a
meta/runtime.yml which can be used by Ansible 2.10+ to automatically use the new module names if the playbook contains the old ones.
Oh, and yes, this is probably not the nicest script you'll read this year. Maybe not even today. But it got the job nicely done and I don't intend to need it again anyways.  After that I got multiple questions about the setup, so I thought "Michael and Michael did posts about their setups, you could too!"
And well, here we are ;-)
desk
The desk is a Flexispot E5B frame with a 200 80 2.6cm oak table top.
The Flexispot E5 (the B stands for black) is a rather cheap (as in not expensive) standing desk frame. It has a retail price of 379 , but you can often get it as low as 299 on sale.
Add a nice table top from a local store (mine was like 99 ), a bit of wood oil and work and you get a nice standing desk for less than 500 .
The frame has three memory positions, but I only use two: one for sitting, one for standing, and a "change position" timer that I never used so far.
The table top has a bit of a swing when in standing position (mine is at 104cm according to the electronics in the table), but not enough to disturb typing on the keyboard or thinking. I certainly wouldn't place a sewing machine up there, but that was not a requirement anyways ;)
To compare: the IKEA Bekant table has a similar, maybe even slightly stronger swing.
chair
Speaking of IKEA The chair is an IKEA Volmar. They don't seem to sell it since mid 2019 anymore though, so no link here.
hardware
laptop
A Lenovo ThinkPad T480s, i7-8650U, 24GB RAM, running Fedora 32 Workstation. Just enough power while not too big and heavy. Full of stickers, because I stickers!
It's connected to a Lenovo ThinkPad Thunderbolt 3 Dock (Gen 1). After 2 years with that thing, I'm still not sure what to think about it, as I had various issues with it over the time:
After that I got multiple questions about the setup, so I thought "Michael and Michael did posts about their setups, you could too!"
And well, here we are ;-)
desk
The desk is a Flexispot E5B frame with a 200 80 2.6cm oak table top.
The Flexispot E5 (the B stands for black) is a rather cheap (as in not expensive) standing desk frame. It has a retail price of 379 , but you can often get it as low as 299 on sale.
Add a nice table top from a local store (mine was like 99 ), a bit of wood oil and work and you get a nice standing desk for less than 500 .
The frame has three memory positions, but I only use two: one for sitting, one for standing, and a "change position" timer that I never used so far.
The table top has a bit of a swing when in standing position (mine is at 104cm according to the electronics in the table), but not enough to disturb typing on the keyboard or thinking. I certainly wouldn't place a sewing machine up there, but that was not a requirement anyways ;)
To compare: the IKEA Bekant table has a similar, maybe even slightly stronger swing.
chair
Speaking of IKEA The chair is an IKEA Volmar. They don't seem to sell it since mid 2019 anymore though, so no link here.
hardware
laptop
A Lenovo ThinkPad T480s, i7-8650U, 24GB RAM, running Fedora 32 Workstation. Just enough power while not too big and heavy. Full of stickers, because I stickers!
It's connected to a Lenovo ThinkPad Thunderbolt 3 Dock (Gen 1). After 2 years with that thing, I'm still not sure what to think about it, as I had various issues with it over the time:
 However, on closer inspection you'll notice that your normal jumper wires don't fit as the Shelly has a connector with 1.27mm (0.05in) pitch and 1mm diameter holes.
Now, there are various tutorials on the Internet how to build a compatible connector using Ethernet cables and hot glue or with female header socket legs, and you can even buy cables on Amazon for 18 ! But 18 sounded like a lot and the female header socket thing while working was pretty finicky to use, so I decided to build something different.
We'll need 6 female-to-female jumper wires and a 1.27mm pitch male header. Jumper wires I had at home, the header I got is a SL 1X20G 1,27 from reichelt.de for 0.61 . It's a 20 pin one, so we can make 3 adapters out of it if needed. Oh and we'll need some isolation tape.
However, on closer inspection you'll notice that your normal jumper wires don't fit as the Shelly has a connector with 1.27mm (0.05in) pitch and 1mm diameter holes.
Now, there are various tutorials on the Internet how to build a compatible connector using Ethernet cables and hot glue or with female header socket legs, and you can even buy cables on Amazon for 18 ! But 18 sounded like a lot and the female header socket thing while working was pretty finicky to use, so I decided to build something different.
We'll need 6 female-to-female jumper wires and a 1.27mm pitch male header. Jumper wires I had at home, the header I got is a SL 1X20G 1,27 from reichelt.de for 0.61 . It's a 20 pin one, so we can make 3 adapters out of it if needed. Oh and we'll need some isolation tape.
 The first step is to cut the header into 6 pin chunks. Make sure not to cut too close to the 6th pin as the whole thing is rather fragile and you might lose it.
The first step is to cut the header into 6 pin chunks. Make sure not to cut too close to the 6th pin as the whole thing is rather fragile and you might lose it.
 It now fits very well into the Shelly with the longer side of the pins.
It now fits very well into the Shelly with the longer side of the pins.
 Second step is to strip the plastic part of one side of the jumper wires. Those are designed to fit 2.54mm pitch headers and won't work for our use case otherwise.
Second step is to strip the plastic part of one side of the jumper wires. Those are designed to fit 2.54mm pitch headers and won't work for our use case otherwise.
 As the connectors are still too big, even after removing the plastic, the next step is to take some pliers and gently press the connectors until they fit the smaller pins of our header.
As the connectors are still too big, even after removing the plastic, the next step is to take some pliers and gently press the connectors until they fit the smaller pins of our header.
 Now is the time to put everything together. To avoid short circuiting the pins/connectors, apply some isolation tape while assembling, but not too much as the space is really limited.
Now is the time to put everything together. To avoid short circuiting the pins/connectors, apply some isolation tape while assembling, but not too much as the space is really limited.
 And we're done, a wonderful (lol) and working (yay) Shelly 2.5 cable that can be attached to any USB-TTL adapter, like the pictured FTDI clone you get almost everywhere.
And we're done, a wonderful (lol) and working (yay) Shelly 2.5 cable that can be attached to any USB-TTL adapter, like the pictured FTDI clone you get almost everywhere.
 Yes, in an ideal world we would have soldered the header to the cable, but I didn't feel like soldering on that limited space. And yes, shrink-wrap might be a good thing too, but again, limited space and with isolation tape you only need one layer between two pins, not two.
Yes, in an ideal world we would have soldered the header to the cable, but I didn't feel like soldering on that limited space. And yes, shrink-wrap might be a good thing too, but again, limited space and with isolation tape you only need one layer between two pins, not two. ssh -R127.0.0.1:2222:127.0.0.1:22 server.example.com will forward localhost:2222 on server.example.com to port 22 of the machine the SSH connection originated from. But what happens if the connection dies? Adding a while true; do ; done around it might help, but I would really like not to reinvent the wheel here!
Thankfully, somebody already invented that particular wheel and OpenWRT comes with a sshtunnel package that takes care of setting up and keeping up such tunnels and documentation how to do so. Just install the sshtunnel package, edit /etc/config/sshtunnel to contain a server stanza with hostname, port and username and a tunnelR stanza referring said server plus the local and remote sides of the tunnel and you're good to go.
config server home
option user user
option hostname server.example.com
option port 22
config tunnelR local_ssh
option server home
option remoteaddress 127.0.0.1
option remoteport 2222
option localaddress 127.0.0.1
option localport 22
sshtunnel needs the OpenSSH client binary (and the package correctly depends on it) and OpenWRT does not ship the ssh-keygen tool from OpenSSH but only the equivalent for Dropbear. As OpenSSH can't read Dropbear keys (and vice versa) you'll have to generate the key somewhere else and deploy it to the OpenWRT box and the target system.
Oh, and OpenWRT defaults to enabling password login via SSH, so please disable that if you expose the box to the Internet in any way!
Using the tunnel
After configuring and starting the service, you'll see the OpenWRT system logging in to the configured remote and opening the tunnel. For some reason that connection would not show up in the output of w -- probably because there was no shell started or something, but logs show it clearly.
Now it's just a matter of connecting to the newly open port and you're in. As the port is bound to 127.0.0.1, the connection is only possible from server.example.com or using it as a jump host via OpenSSH's ProxyJump option: ssh -J server.example.com -p 2222 root@localhost.
Additionally, you can forward a local port over the tunneled connection to create a tunnel for the OpenWRT webinterface: ssh -J server.example.com -p 2222 -L8080:localhost:80 root@localhost. Yes, that's a tunnel inside a tunnel, and all the network engineers will go brrr, but it works and you can access LuCi on http://localhost:8080 just fine.
If you don't want to type that every time, create an entry in your .ssh/config:
Host openwrt
ProxyJump server.example.com
HostName localhost
Port 2222
User root
LocalForward 8080 localhost:80
esphome:
name: shelly25
platform: ESP8266
board: modwifi
arduino_version: 2.4.2
board: modwifi as the Shelly 2.5 (and all other Shellys) has 2MB flash and the usually recommended esp01_1m would only use 1MB of that - otherwise the configurations are identical (see the PlatformIO entries for modwifi and esp01_1m). And arduino_version: 2.4.2 is what the Internet suggests is the most stable SDK version, and who will argue with the Internet?!
Now an ESP8266 without network connection is boring, so we add a WiFi configuration:
wifi:
ssid: !secret wifi_ssid
password: !secret wifi_password
power_save_mode: none
!secret commands load the named variables from secrets.yaml. While testing, I found the network connection of the Shelly very unreliable, especially when placed inside the wall and thus having rather bad bad reception (-75dBm according to ESPHome). However, setting power_save_mode: none explicitly seems to have fixed this, even if NONE is supposed to be the default on ESP8266.
At this point the Shelly has a working firmware and WiFi, but does not expose any of its features: no switches, no relays, no power meters.
To fix that we first need to find out the GPIO pins all these are connected to. Thankfully we can basically copy paste the definition from the Tasmota (another open-source firmware for ESPs) template:
pin_led1: GPIO0
pin_button1: GPIO2
pin_relay1: GPIO4
pin_switch2n: GPIO5
pin_sda: GPIO12
pin_switch1n: GPIO13
pin_scl: GPIO14
pin_relay2: GPIO15
pin_ade7953: GPIO16
pin_temp: A0
substitutions section of the ESPHome config, we can use the names everywhere and don't have to remember the pin numbers.
The configuration for the ADE7953 power sensor and the NTC temperature sensor are taken verbatim from the ESPHome documentation, so there is no need to repeat them here.
The configuration for the switches and relays are also rather straight forward:
binary_sensor:
- platform: gpio
pin: $ pin_switch1n
name: "Switch #1"
internal: true
id: switch1
- platform: gpio
pin: $ pin_switch2n
name: "Switch #2"
internal: true
id: switch2
switch:
- platform: gpio
pin: $ pin_relay1
name: "Relay #1"
internal: true
id: relay1
interlock: &interlock_group [relay1, relay2]
- platform: gpio
pin: $ pin_relay2
name: "Relay #2"
internal: true
id: relay2
interlock: *interlock_group
internal: true, as we don't need them visible in Home Assistant.
ESPHome and Schellenberg roller shutters
Now that we have a working Shelly 2.5 with ESPHome, how do we control Schellenberg (and other) roller shutters with it?
Well, first of all we need to connect the Up and Down wires of the shutter motor to the two relays of the Shelly. And if they would not be marked as internal: true, they would show up in Home Assistant and we would be able to flip them on and off, moving the shutters. But this would also mean that we need to flip them off each time after use, as while the motor knows when to stop and will do so, applying current to both wires at the same time produces rather interesting results. So instead of fiddling around with the relays directly, we define a time-based cover in our configuration:
cover:
- platform: time_based
name: "$ location Rolladen"
id: rolladen
open_action:
- switch.turn_on: relay2
open_duration: $ open_duration
close_action:
- switch.turn_on: relay1
close_duration: $ close_duration
stop_action:
- switch.turn_off: relay1
- switch.turn_off: relay2
on_press automations to the binary GPIO sensors we configured for the two switch inputs the Shelly has. But if you have kids at home, you'll know that they like to press ALL THE THINGS and what could be better than a small kill-switch against small fingers?
switch:
[ previous definitions go here ]
- platform: template
id: block_control
name: "$ location Block Control"
optimistic: true
- platform: template
name: "Move UP"
internal: true
lambda: -
if (id(switch1).state && !id(block_control).state)
return true;
else
return false;
on_turn_on:
then:
cover.open: rolladen
on_turn_off:
then:
cover.stop: rolladen
- platform: template
name: "Move DOWN"
internal: true
lambda: -
if (id(switch2).state && !id(block_control).state)
return true;
else
return false;
on_turn_on:
then:
cover.close: rolladen
on_turn_off:
then:
cover.stop: rolladen
lambda definition and is set to optimistic: true, which makes is basically a dumb switch that can be flipped at will and the only thing it does is storing the binary on/off state.
The two others are almost identical. The name differs, obviously, and so does the on_turn_on automation (one triggers the cover to open, the other to close). And the really interesting part is the lambda that monitors one of the physical switches and if that is turned on, plus "Block Control" is off, reports the switch as turned on, thus triggering the automation.
With this we can now block the physical switches via Home Assistant, while still being able to control the shutters via the same.
All this (and a bit more) can be found in my esphome-configs repository on GitHub, enjoy!  Here is my monthly update covering what I have been doing in the free software world (previous month):
Here is my monthly update covering what I have been doing in the free software world (previous month):
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues.
buildinfo.debian.net is my experiment into how to process, store and distribute .buildinfo files after the Debian archive software has processed them.
strip-nondeterminism is our tool to remove specific non-deterministic results from a completed build.
Here is my monthly update covering what I have been doing in the free software world (previous month):
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues.
buildinfo.debian.net is my experiment into how to process, store and distribute .buildinfo files after the Debian archive software has processed them.
 As web search engines and IRC seems to be of no help, maybe someone
here has a helpful idea. I have some service written in python that
comes with a .service file for systemd. I now want to build&install a
working service file from the software's setup.py. I can override
the build/build_py commands of setuptools, however that way I still
lack knowledge wrt. the bindir/prefix where my service script will be
installed.
Solution
Turns out, if you override the
As web search engines and IRC seems to be of no help, maybe someone
here has a helpful idea. I have some service written in python that
comes with a .service file for systemd. I now want to build&install a
working service file from the software's setup.py. I can override
the build/build_py commands of setuptools, however that way I still
lack knowledge wrt. the bindir/prefix where my service script will be
installed.
Solution
Turns out, if you override the install command (not the
install_data!), you will have self.root and self.install_scripts
(and lots of other self.install_*). As a result, you can read the
template and write the desired output file after calling super's
run method. The fix was inspired by GateOne (which, however
doesn't get the --root parameter right, you need to strip
self.root from the beginning of the path to actually make that work
as intended).
As suggested on IRC, the snippet (and my software) no use pkg-config
to get at the systemd path as well. This is a nice improvement
orthogonal to the original problem. The implementation here follows
bley.
def systemd_unit_path():
try:
command = ["pkg-config", "--variable=systemdsystemunitdir", "systemd"]
path = subprocess.check_output(command, stderr=subprocess.STDOUT)
return path.decode().replace('\n', '')
except (subprocess.CalledProcessError, OSError):
return "/lib/systemd/system"
class my_install(install):
_servicefiles = [
'foo/bar.service',
]
def run(self):
install.run(self)
if not self.dry_run:
bindir = self.install_scripts
if bindir.startswith(self.root):
bindir = bindir[len(self.root):]
systemddir = "%s%s" % (self.root, systemd_unit_path())
for servicefile in self._servicefiles:
service = os.path.split(servicefile)[1]
self.announce("Creating %s" % os.path.join(systemddir, service),
level=2)
with open(servicefile) as servicefd:
servicedata = servicefd.read()
with open(os.path.join(systemddir, service), "w") as servicefd:
servicefd.write(servicedata.replace("%BINDIR%", bindir))
diffoscope is our "diff on steroids" that will not only recursively unpack archives but will transform binary formats into human-readable forms in order to compare them.
disorderfs is our FUSE filesystem that deliberately introduces nondeterminism into the results of system calls such as readdir(3).
strip-nondeterminism is our tool to remove specific information from a completed build.

I attended the Debian Bug Squashing Party (BSP) in Salzburg, Austria where 70+ "release-critical" bugs were fixed. Sincere thanks to Bernd Zeimetz (bzed) for organising and Conova for sponsoring/hosting. The event was covered by the Salzburg Cityguide.
I attended NixOS user group in London, England.
Niels Thykier granted me commit access to the Lintian Git repository and I added myself to the debian/copyright there.
Filed an ITP for the roughtime secure time synchronisation client and server. This is blocked on packaging the Bazel build system. (#838416)
 I am happy to announce the release of OASIS v0.4.7.
I am happy to announce the release of OASIS v0.4.7.
On Saturday (around 17:00) I upgraded to Froxlor 0.9.35.1 to get Let's Encrypt support and hit Froxlor bug 1615 without noticing as PowerDNS re-reads zones.conf only when told.
On Sunday PowerDNS was restarted because of upgraded packages, thus re-reading zones.conf and properly logging:
May 15 08:10:59 shokki pdns[2210]: [bindbackend] Parsing 0 domain(s), will report when done
On Tuesday the issue hit a friend who cared and notified me
On Tuesday the issue was fixed (first by a quick restore from etckeeper, later by fixing the generating code):
May 17 14:56:08 shokki pdns[24422]: [bindbackend] Parsing 15 domain(s), will report when done
__DATE__ / __TIME__) has been applied upstream and will be released with GCC 7.
Following that Matthias Klose also has uploaded gcc-5/5.3.1-17 and gcc-6/6.1.1-1 to unstable with a backport of that SOURCE_DATE_EPOCH patch.
Emmanuel Bourg uploaded maven/3.3.9-4, which uses SOURCE_DATE_EPOCH for the maven.build.timestamp.
(SOURCE_DATE_EPOCH specification)
Other upstream changes
Alexis Bienven e submitted a patch to Sphinx which extends SOURCE_DATE_EPOCH support for copyright years in generated documentation.
Packages fixed
The following 12 packages have become reproducible due to changes in their
build dependencies:
hhvm
jcsp
libfann
libflexdock-java
libjcommon-java
libswingx1-java
mobile-atlas-creator
not-yet-commons-ssl
plexus-utils
squareness
svnclientadapter
The following packages have became reproducible after being fixed:
convert.pl honor SOURCE_DATE_EPOCH. Original patch by Jerome Benoit, duplicate patch by Dhole.SOURCE_DATE_EPOCH is set.SOURCE_DATE_EPOCH support to copyright year.
Packages fixed
The following packages have become reproducible due to changes in their
build dependencies:
atinject-jsr330,
avis,
brailleutils,
charactermanaj,
classycle,
commons-io,
commons-javaflow,
commons-jci,
gap-radiroot,
jebl2,
jetty,
libcommons-el-java,
libcommons-jxpath-java,
libjackson-json-java,
libjogl2-java,
libmicroba-java,
libproxool-java,
libregexp-java,
mobile-atlas-creator,
octave-econometrics,
octave-linear-algebra,
octave-odepkg,
octave-optiminterp,
rapidsvn,
remotetea,
ruby-rinku,
tachyon,
xhtmlrenderer.
The following packages became reproducible after getting fixed:
config.h file, and honour SOURCE_DATE_EPOCH when creating the config.h file./bin/sh as shell..edp files, and honour SOURCE_DATE_EPOCH when using the build date.SOURCE_DATE_EPOCH environment variable through the ustrftime function, to get a reproducible copyright year.fim binary, make the embeded vim2html script honour SOURCE_DATE_EPOCH variable when building the documentation, and force language to be English when using bison to make a grammar that is going to be parsed using English keywords.dh-buildinfo. A good amount of the Debian reproducible
builds team had the chance to
enjoy face-to-face interactions during DebConf15.
A good amount of the Debian reproducible
builds team had the chance to
enjoy face-to-face interactions during DebConf15.
 |
 Toolchain fixes
Toolchain fixes
__repr__ so memory addresses don't appear in docs (#795826). Patches by Val Lorentz.erlc. Patch by Chris West (Faux) and Chris Lamb..file to the assembler output.-d option to txt2man and add the --date option to override the current date.SOURCE_DATE_EPOCH instead of the custom WHEEL_FORCE_TIMESTAMP. akira sent one making man2html SOURCE_DATE_EPOCH aware.
St phane Glondu reported that dpkg-source would not respect tarball permissions when unpacking under a umask of 002.
After hours of iterative testing during the DebConf workshop, Sandro Knau created a test case showing how pdflatex output can be non-deterministic with some PNG files.
Packages fixed
The following 65 packages became reproducible due to changes in their
build dependencies:
alacarte,
arbtt,
bullet,
ccfits,
commons-daemon,
crack-attack,
d-conf,
ejabberd-contrib,
erlang-bear,
erlang-cherly,
erlang-cowlib,
erlang-folsom,
erlang-goldrush,
erlang-ibrowse,
erlang-jiffy,
erlang-lager,
erlang-lhttpc,
erlang-meck,
erlang-p1-cache-tab,
erlang-p1-iconv,
erlang-p1-logger,
erlang-p1-mysql,
erlang-p1-pam,
erlang-p1-pgsql,
erlang-p1-sip,
erlang-p1-stringprep,
erlang-p1-stun,
erlang-p1-tls,
erlang-p1-utils,
erlang-p1-xml,
erlang-p1-yaml,
erlang-p1-zlib,
erlang-ranch,
erlang-redis-client,
erlang-uuid,
freecontact,
givaro,
glade,
gnome-shell,
gupnp,
gvfs,
htseq,
jags,
jana,
knot,
libconfig,
libkolab,
libmatio,
libvsqlitepp,
mpmath,
octave-zenity,
openigtlink,
paman,
pisa,
pynifti,
qof,
ruby-blankslate,
ruby-xml-simple,
timingframework,
trace-cmd,
tsung,
wings3d,
xdg-user-dirs,
xz-utils,
zpspell.
The following packages became reproducible after getting fixed:
debian/changelog entry.debian/changelog entry.LC_ALL set to C.debian/changelog entry.LC_ALL set to C.lib/Lucy.xs in a deterministic order.LC_ALL set to C.aff files generated by mk_he_affix.icalderivedvalue.c.debian/changelog entry.debian/changelog entry.debian/changelog entry.U flag to ar.
Reiner Herrmann reported an issue with pound which embeds random dhparams in its code during the build. Better solutions are yet to be found.
reproducible.debian.net
Package pages on reproducible.debian.net now have a new layout improving readability designed by Mattia Rizzolo, h01ger, and Ulrike. The navigation is now on the left as vertical space is more valuable nowadays.
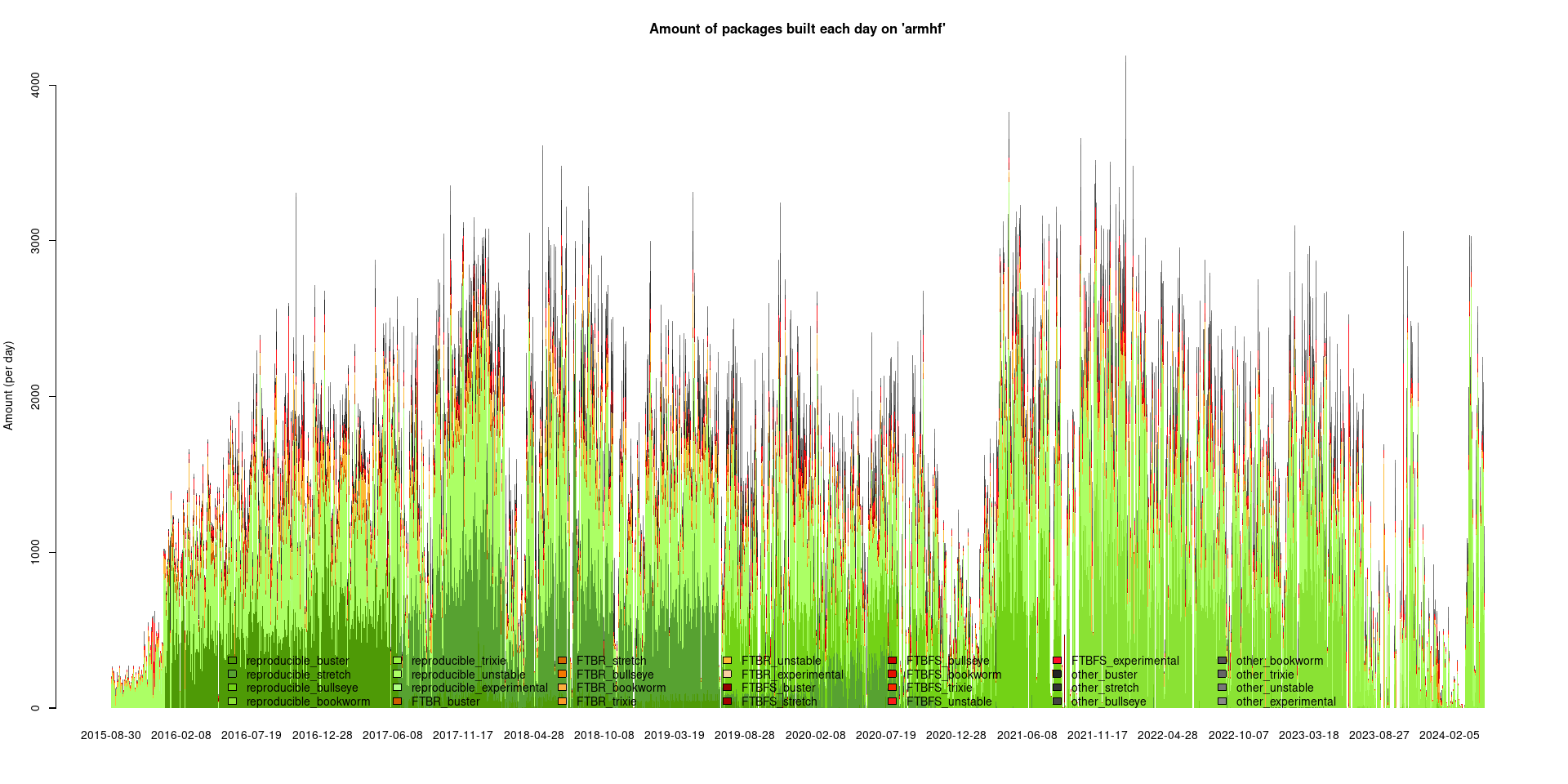
armhf is now enabled on all pages except the dashboard. Actual tests on armhf are expected to start shortly. (Mattia Rizzolo, h01ger)
The limit on how many packages people can schedule using the reschedule script on Alioth has been bumped to 200. (h01ger)
mod_rewrite is now used instead of JavaScript for the form in the dashboard. (h01ger)
Following the rename of the software, debbindiff has mostly been replaced by either diffoscope or differences in generated HTML and IRC notification output.
Connections to UDD have been made more robust. (Mattia Rizzolo)
diffoscope development
diffoscope version 31 was released on August 21st. This version improves fuzzy-matching by using the tlsh algorithm instead of ssdeep.
New command line options are available: --max-diff-input-lines and --max-diff-block-lines to override limits on diff input and output (Reiner Herrmann), --debugger to dump the user into pdb in case of crashes (Mattia Rizzolo).
jar archives should now be detected properly (Reiner Herrman). Several general code cleanups were also done by Chris Lamb.
strip-nondeterminism development
Andrew Ayer released strip-nondeterminism version 0.010-1. Java properties file in jar should now be detected more accurately. A missing dependency spotted by St phane Glondu has been added.
Testing directory ordering issues: disorderfs
During the reproducible builds workshop at DebConf, participants identified that we were still short of a good way to test variations on filesystem behaviors (e.g. file ordering or disk usage). Andrew Ayer took a couple of hours to create disorderfs. Based on FUSE, disorderfs in an overlay filesystem that will mount the content of a directory at another location. For this first version, it will make the order in which files appear in a directory random.
Documentation update
Dhole documented how to implement support for SOURCE_DATE_EPOCH in Python, bash, Makefiles, CMake, and C.
Chris Lamb started to convert the wiki page describing SOURCE_DATE_EPOCH into a Freedesktop-like specification in the hope that it will convince more upstream to adopt it.
Package reviews
44 reviews have
been removed, 192 added and 77 updated this week.
New issues identified this week: locale_dependent_order_in_devlibs_depends, randomness_in_ocaml_startup_files, randomness_in_ocaml_packed_libraries, randomness_in_ocaml_custom_executables, undeterministic_symlinking_by_rdfind, random_build_path_by_golang_compiler, and images_in_pdf_generated_by_latex.
117 new FTBFS bugs have been reported by Chris Lamb, Chris West (Faux), and Niko Tyni.
Misc.
Some reproducibility issues might face us very late. Chris Lamb noticed that the test suite for python-pykmip was now failing because its test certificates have expired. Let's hope no packages are hiding a certificate valid for 10 years somewhere in their source!
Pictures courtesy and copyright of Debian's own paparazzi: Aigars Mahinovs.
Next.
{kind=link}